 Home-theater-designers
Home-theater-designers
Jos käytät Pythonia jopa yksinkertaisimpiin tehtäviin, olet todennäköisesti tietoinen sen kolmannen osapuolen kirjastojen tärkeydestä. Pandas-kirjasto, jolla on erinomainen tuki DataFramesille, on yksi tällainen kirjasto.
Python DataFramesiin voi tuoda useita tiedostoja ja luoda erilaisia versioita eri tietojoukkojen tallentamiseksi. Kun tuot tietosi DataFrame-kehyksillä, voit yhdistää ne suorittaaksesi yksityiskohtaisen analyysin.
Perusasioiden käsitteleminen
Ennen kuin aloitat yhdistämisen, sinulla on oltava DataFrames yhdistämistä varten. Kehitystarkoituksiin voit luoda valedataa kokeiltavaksi.
Luo DataFrames Pythonissa
Ensimmäisenä vaiheena tuo Pandas-kirjasto Python-tiedostoon. Pandas on kolmannen osapuolen kirjasto, joka käsittelee DataFrame-tiedostoja Pythonissa. Voit käyttää tuonti lausunto kirjaston käytöstä seuraavasti:
import pandas as pdVoit määrittää kirjaston nimelle aliaksen lyhentääksesi koodiviittauksiasi.
Sinun on luotava sanakirjoja, jotka voit muuntaa DataFrame-kehyksiksi. Saat parhaat tulokset luomalla kaksi sanakirjamuuttujaa – sanelu1 ja sanelu 2- tallentaaksesi tiettyjä tietoja:
kuinka estää puhelimen ylikuumeneminen
dict1 = {"user_id": ["001", "002", "003", "004", "005"],
"FName": ["John", "Brad", "Ron", "Roald", "Chris"],
"LName": ["Harley", "Cohen", "Dahl", "Harrington", "Kerr-Hislop"]}
dict2 = {"user_id": ["001", "002", "003", "004"], "Age": [15, 28, 34, 24]}Muista, että molemmissa sanakirjan arvoissa on oltava yhteinen elementti, jotta se toimii ensisijaisena avaimena datakehysten yhdistämiselle myöhemmin.
Muunna sanakirjasi tietokehyksiksi
Voit muuntaa sanakirja-arvot DataFrame-kehyksiksi käyttämällä seuraavaa menetelmää:
df1 = pd.DataFrame(dict1)
df2 = pd.DataFrame(dict2)Jotkin IDE:t antavat sinun tarkistaa DataFramen arvot viittaamalla DataFrame-toimintoon ja painamalla Suorita/Suorita . On olemassa monia Python-yhteensopivat IDE:t , joten voit valita sen, joka on sinulle helpoin oppia.

Kun olet tyytyväinen DataFrame-kehystesi sisältöön, voit siirtyä yhdistämisvaiheeseen.
Kehysten yhdistäminen yhdistämistoiminnolla
Yhdistämistoiminto on ensimmäinen Python-toiminto, jolla voit yhdistää kaksi DataFrame-kehystä. Tämä funktio ottaa seuraavat oletusargumentit:
pd.merge(DataFrame1, DataFrame2, how= type of merge)Missä:
- pd on Pandas-kirjaston alias.
- yhdistää on toiminto, joka yhdistää DataFrame-kehykset.
- DataFrame1 ja DataFrame2 ovat kaksi DataFrame-kehystä, jotka yhdistetään.
- Miten määrittää yhdistämistyypin.
Saatavilla on joitain ylimääräisiä valinnaisia argumentteja, joita voit käyttää, kun tietorakenne on monimutkainen.
Voit käyttää eri arvoja miten-parametrille määrittämään suoritettavan yhdistämisen tyyppi. Tämäntyyppiset yhdistämiset ovat tuttuja, jos olet käytti SQL:ää tietokantataulukoiden yhdistämiseen .
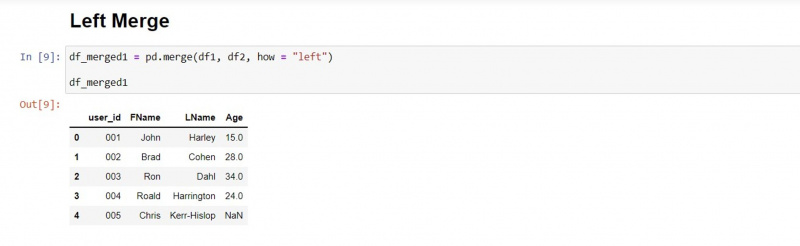
Vasen yhdistäminen
Vasen yhdistämistyyppi pitää ensimmäisen DataFramen arvot ennallaan ja hakee vastaavat arvot toisesta DataFramesta.
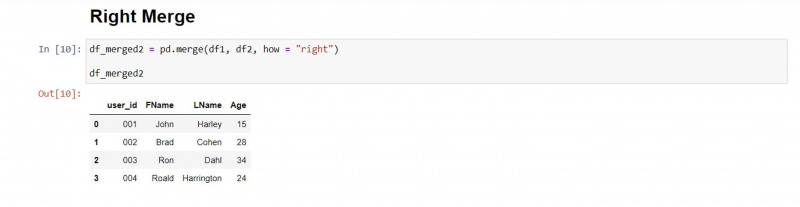
Oikea yhdistäminen
Oikea yhdistämistyyppi pitää toisen DataFramen arvot ennallaan ja hakee vastaavat arvot ensimmäisestä DataFramesta.
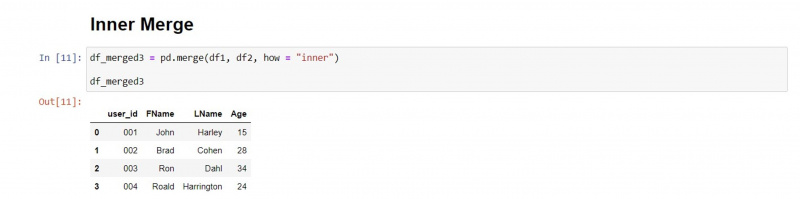
Sisäinen yhdistäminen
Sisäinen yhdistämistyyppi säilyttää vastaavat arvot molemmista DataFrame-kehyksistä ja poistaa ei-vastaavat arvot.
Ulompi yhdistäminen
Ulompi yhdistämistyyppi säilyttää kaikki vastaavat ja ei-vastaavat arvot ja yhdistää DataFrame-kehykset yhteen.
kuinka löytää imei -numero iphone

Concat-funktion käyttäminen
The concat -toiminto on joustava vaihtoehto verrattuna joihinkin Pythonin muihin yhdistämistoimintoihin. Concat-toiminnolla voit yhdistää DataFrame-kehykset pysty- ja vaakasuunnassa.
Tämän toiminnon käytön haittana on kuitenkin se, että se hylkää oletusarvoisesti kaikki yhteensopimattomat arvot. Kuten joillakin muillakin vastaavilla funktioilla, tällä funktiolla on muutamia argumentteja, joista vain muutama on välttämätön onnistuneelle ketjutukselle.
concat(dataframes, axis=0, join='outer'/’inner’)Missä:
- concat on funktio, joka yhdistää DataFrame-kehykset.
- tietokehykset on datakehysten sarja ketjutettavaksi.
- akseli edustaa ketjutuksen suuntaa, 0 on vaaka, 1 on pystysuora.
- liittyä seuraan määrittää joko ulko- tai sisäliitoksen.
Yllä olevia kahta DataFramea käyttämällä voit kokeilla concat-toimintoa seuraavasti:
C7D9532E6E400D036831857B2E2FD81842F4HELMIAkseli- ja liitosargumenttien puuttuminen yllä olevassa koodissa yhdistää nämä kaksi tietojoukkoa. Tuloksena oleva tulos sisältää kaikki merkinnät sovituksen tilasta riippumatta.
Vastaavasti voit käyttää lisäargumentteja concat-funktion suunnan ja tulosteen ohjaamiseen.
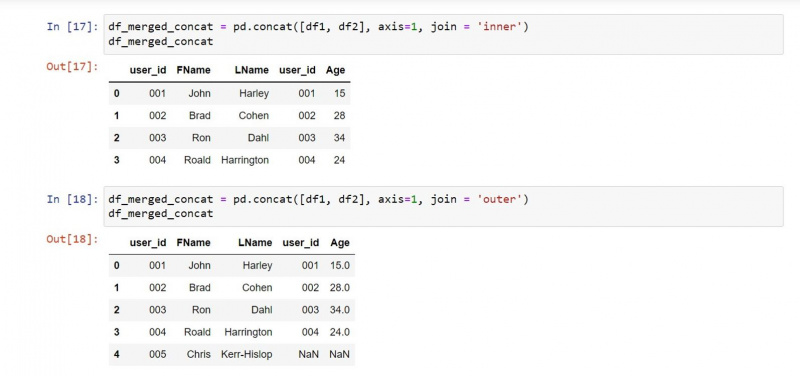
Voit ohjata tulostetta kaikilla vastaavilla merkinnöillä:
# Concatenating all matching values between the two dataframes based on their columns
df_merged_concat = pd.concat([df1, df2], axis=1, join = 'inner')
print(df_merged_concat)Tulos sisältää vain kaikki vastaavat arvot kahden DataFrame-kehyksen välillä.
Datakehysten yhdistäminen Pythonin kanssa
DataFrame-kehykset ovat olennainen osa Pythonia, kun otetaan huomioon niiden joustavuus ja toimivuus. Niiden monipuolisen käyttötarkoituksen vuoksi voit käyttää niitä laajasti erilaisten tehtävien suorittamiseen äärimmäisen helposti.
Jos opit edelleen Python DataFrame -kehyksistä, kokeile tuoda joitain Excel-tiedostoja ja yhdistää ne sitten erilaisiin lähestymistapoihin.